devworld.apple.com
February 14, 2020

capture details
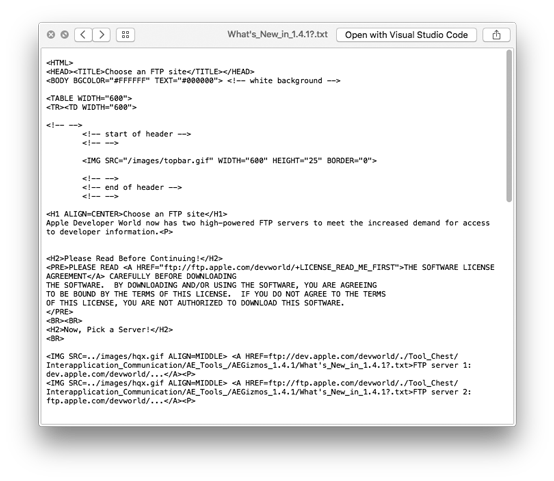 Several thousand .txt files like the one illustrated above were purged because their contents were simply html documents referencing legacy Apple ftp servers.
Several thousand .txt files like the one illustrated above were purged because their contents were simply html documents referencing legacy Apple ftp servers.
With over 40,000 folders, the devworld.apple.com_rest_IA download presented its own specific challenges — a whole lot of child folders from desktop to FTP
It should be understood that each waybackmachine snapshot creates a small directory tree inside of a parent folder, each of which are assigned names as per the 19970616061813 example tree below.
➜ Blot tree /Users/admin/Desktop/19970616061813
/Users/admin/Desktop/19970616061813
└── dev
└── techsupport
└── insidemac
└── QuickDraw3D
└── chap18_pointingdevice
└── QuickDraw3D-1087.htmlThe challenge for any download you find on this site invariably requires he child directory to be isolated from the parent so that a merge can occur because the parent has a unique name which means a merge can’t occur from there. One merge occurs an approachable a readable directory emerges.
At first, ditto was considered but it appears best suited for a single source and destination folder. Until a diff merge or other merge tool is found, child folders must be isolated from the parent and manually dropped to an FTP server. A properly configured FTP client does a masterful job at merging, the results of which yield a directory tree worthy of inspection.
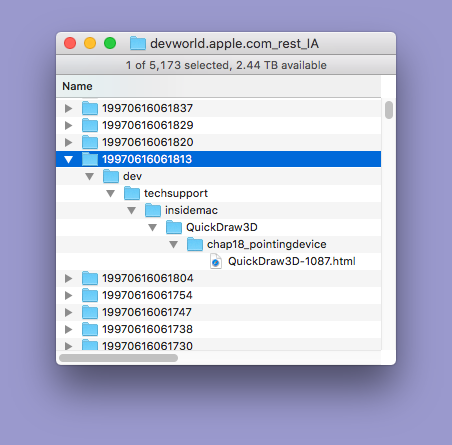 A portion of a Finder window displaying a single parent recursively revealing its directory tree. Notice the single ‘dev’ child folder.
A portion of a Finder window displaying a single parent recursively revealing its directory tree. Notice the single ‘dev’ child folder.
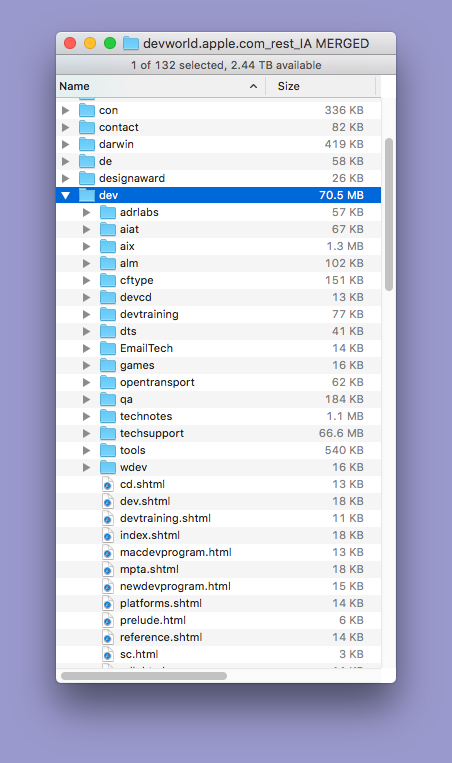 The ‘dev’ folder after it was merged, disclosing its contents.
The ‘dev’ folder after it was merged, disclosing its contents.
Two separate scrapes were performed
File listing for Scrape 1 smi|hqx|sit|dd|pkg|abs|bin|sea|cpt|dmg (for .co.jp TLD)
Download the zip file
wayback_machine_downloader -s -d devworld.apple.com_onlybin_IA -t2003 -c6 --only "/\.(smi|hqx|sit|dd|pkg|abs|bin|sea|cpt|dmg)$/i" devworld.apple.comTree
tree -N -shQDF --charset /path/to/parent/dir > devworld.apple.com_onlybin_IA_tree.txtContents list
find /path/to/parent/dir -not -name '.*' -type file -exec basename {} \;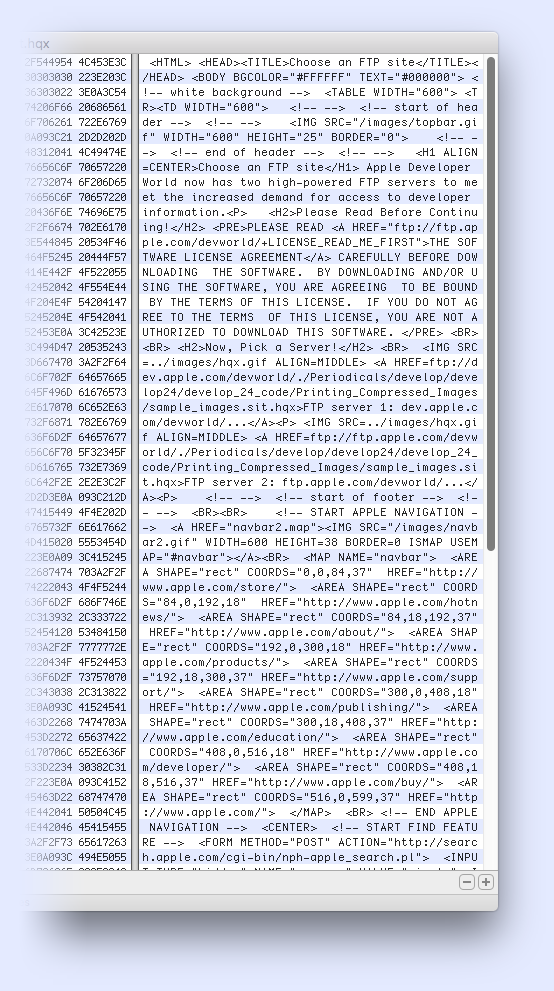 Unfortunately this capture yielded a flurry of mostly 4KB .sit and .hqx files whose contents are nothing more then HTML documents as illustrated by the hexeditor window above. These incomplete files may be available in full on some of Apple’s Dev/Tool discs but until trees or listings of their contents are output this can’t be verified.
Unfortunately this capture yielded a flurry of mostly 4KB .sit and .hqx files whose contents are nothing more then HTML documents as illustrated by the hexeditor window above. These incomplete files may be available in full on some of Apple’s Dev/Tool discs but until trees or listings of their contents are output this can’t be verified.
File Types for Scrape 2 html|htm|shtml|pdf|jpg|gif|png|tng
Out of curiosity this capture deliberately scraped beyond the proposed scope of file types usually considered.
Download the scrape 2 file repository as a zip
Download the first scrape file repository as a zip
wayback_machine_downloader -s -d devworld.apple.com_onlybin_IA -t2003 -c6 --only "/\.(smi|hqx|sit|dd|pkg|abs|bin|sea|cpt|dmg)$/i" devworld.apple.comCreate a tree file
tree -N -shQDF --charset /path/to/parent/dir > devworld.apple.com_onlybin_IA_tree.txtView the content list
find /path/to/parent/dir -not -name '.*' -type file -exec basename {} \;If you are interested in the wayback machine learn more about it and the wayback machine API.
Below is a curious URL that provides a way to filter results (i.e. ‘txt’):
http://web.archive.org/*/www.yoursite.com/*